About me
Ciao! I am Roberto Amoroso, a Senior Research Engineer at NVIDIA in Munich, Germany 🇩🇪, where I build Multimodal Video Understanding and Vision-Language Models (VLMs) systems for large-scale text–image and text–video retrieval, with a focus on Autonomous Vehicle applications.
My work focuses on retrieval architectures that align language with visual signals at scale, enabling users and systems to find relevant moments, objects, and scenes in large image and video collections.
I genuinely enjoy turning research ideas into practical, high-impact solutions.
I completed my PhD through the ELLIS program and the International Doctorate in ICT at the AImageLab research group of the University of Modena and Reggio Emilia (UNIMORE) 🇮🇹, under the supervision of Prof. Rita Cucchiara and Prof. Lorenzo Baraldi.
During my PhD, I also completed a PhD internship at LMU - Ludwig-Maximilians-Universität of Munich, in Germany 🇩🇪, focusing on Multimodal LLM for Video Question Answering and Open-vocabulary Segmentation, under the co-supervision of Prof. Volker Tresp.
I was also a Research Scholar at the Networking Research Group in Saint Louis, USA 🇺🇸, working on Super-resolution techniques applied to Internet traffic matrices.
My primary areas of research are Multimodal Video Understanding and Vision-Language Models for information retrieval, with a focus on MLLM-based text-to-visual retrieval architectures for both images and videos. In addition, I have also conducted research on the pre-training and optimization of Transformer-based architecture for image classification, open-vocabulary segmentation, self-supervised learning, deepfake detection of synthetic images, and the development of image watermarking systems.
Feel free to reach me out if you have any questions or curiosities! :)
- Computer Vision
- Deep Learning
- Machine Learning
- Multimodal Video Understanding
- Vision-Language Models
- Text-to-Visual Retrieval
ELLIS PhD in AI and Computer Vision, 2024
UNIMORE, Italy 🇮🇹 | LMU, Germany 🇩🇪 | NVIDIA, Germany 🇩🇪
MS in Artificial Intelligence, 2020
UNIMORE, Italy 🇮🇹 | AGH, Poland 🇵🇱 | Saint Louis University, USA 🇺🇸
BS in Computer Engineering, 2018
UNIMORE, Italy 🇮🇹
Recent News
- [Jun. 2025] Presenting @ NVIDIA GTC Paris 🇫🇷 a live demo of VLM-powered multimodal video–text retrieval systems for autonomous vehicles.
- [May 2025] Released “Cosmos-Embed1: A Joint Video-Text Embedder for Physical AI” @ NVIDIA a novel video-text embedder tailored for physical AI applications, including autonomous vehicle and robotics.
- [Apr. 2025] Successfully defended my PhD thesis cum laude (with highest honors) titled “Multimodal Attentive Deep Learning Architectures for Visual-Semantic Understanding” 🎓🎉
- [Jan. 2025] Started a new position as Senior Research Engineer @ NVIDIA in Munich, Germany 🇩🇪, working on Multimodal Video Understanding for Autonomous Vehicles
- [Jan. 2025] Our paper “MaPeT: Learning to Mask and Permute Visual Tokens for Vision Transformer Pre-Training” has been accepted @ CVIU 2025
- [Oct. 2024] Our paper “Perceive, Query & Reason: Enhancing Video QA with Question-Guided Temporal Queries” has been accepted @ WACV 2025
- [Oct. 2024] Our paper “Video Search: A Large-scale Video-Text Retrieval System for AV” has been accepted @ NTECH 2024 NVIDIA conference
- [Sep. 2024] Recognized as an Outstanding Reviewer @ ECCV 2024
- [May 2024] Our paper “Parents and Children: Distinguishing Multimodal DeepFakes from Natural Images” has been accepted @ TOMM 2024
- [Feb. 2024] ✨ Our paper “FreeDA: Training-Free Open-Vocabulary Segmentation with Offline Diffusion-Augmented Prototype Generation” has been accepted @ CVPR 2024 in Seattle 🇺🇸. Visit our project page 👉 here
- [Feb. 2024] Started a new position as Machine Learning Engineering Intern @ NVIDIA in Munich, Germany 🇩🇪, working on Multimodal Video Understanding for Autonomous Vehicles
- [Jan. 2024] 2 papers presented @ WACV 2024 in Hawaii 🇺🇸: “FOSSIL: Free Open-Vocabulary Semantic Segmentation through Synthetic References Retrieval” & “What’s Outside the Intersection? Fine-grained Error Analysis for Semantic Segmentation Beyond IoU”
All news »
Experience
- Successfully defended cum laude (with highest honors) my PhD thesis titled “Multimodal Attentive Deep Learning Architectures for Visual-Semantic Understanding”.
- The European Laboratory for Learning and Intelligent Systems (ELLIS) supports cutting-edge machine learning research in Europe. ELLIS PhD students (<5% 2021 acceptance rate) are selected on the basis of academic achievement. My research activity is focused on multimodal machine learning, image segmentation, image classification, self-supervised learning, video retrieval, and video question answering.
- 1st in the ranking of student candidates for the International Doctorate in ICT.
HumanE-AI-NET project, funded by the EU Framework Programme for Research and Innovation Horizon 2020.- Conducted research to develop my MS thesis, winner of the Best Poster Award at CoNEXT 2020.
- Completed the following courses: Advanced Python Programming | Computer Vision | Cybersecurity and Cryptography | Programming in Javascript | Mobile App Development
Honors and Awards
- [Apr. 2025] PhD cum laude (with highest honors) for my PhD thesis “Multimodal Attentive Deep Learning Architectures for Visual-Semantic Understanding” @ UNIMORE
- [Sep. 2024] Outstanding Reviewer Award @ ECCV 2024
- [Sep. 2023] Best Project Award @ ELLIS Summer School on Large-Scale AI for the project “Radioactive Watermarks”, in which we investigate the “radioactivity” of watermarked texts, i.e. , whether they contaminate other models when used as fine-tuning data. The project was evaluated by Tal Hassner (Meta AI) and Marc’Aurelio Ranzato (DeepMind)
- [Jul. 2022] ICVSS 2022 Reading Group Competition Award sponsored by Amazon Web Services (AWS) @ ICVSS 2022 for participation in the reading group led by Prof. Dr. Stefano Soatto (AWS and University of California Los Angeles)
- [Mar. 2022] Best Paper Award sponsored by NVIDIA @ ICIAP 2021 for our paper “Investigating Bidimensional Downsampling in Vision Transformer Models”
- [Dec. 2020] Best Poster Award @ CoNEXT 2020 for our paper “Estimation of Traffic Matrices via Super-resolution and Federated Learning”
Publications
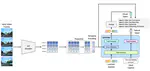


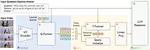
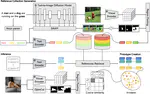
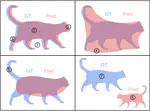





Professional Activities
Reviewer
- International Conference on Computer Vision and Pattern Recognition (CVPR)
- International Conference on Computer Vision (ICCV)
- European Conference on Computer Vision (ECCV)
- Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
- Association for the Advancement of Artificial Intelligence (AAAI)
- IEEE Transactions on Multimedia (TMM)
- Pattern Recognition Letters (PRL)
- ACM Multimedia (ACMMM)
- International Conference on Pattern Recognition (ICPR)