Roberto Amoroso
Roberto Amoroso
Home
News
Experience
Awards
Publications
Activities
Contact
Light
Dark
Automatic
Autonomous Vehicle
Scalable Parallel Prompting for Complex AV Video Captioning
[ CVPRW 2026 ]
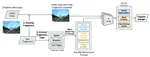
We propose
pSVLMs
, a scalable video captioning framework based on small VLMs that produces diverse intermediate captions, which are consolidated into a comprehensive unified description for autonomous driving datasets.
April Yang
,
Roberto Amoroso
,
Nikita Durasov
,
Devansh Bisla
,
Sandipan Kundu
,
Elmar Haussmann
,
Ruchi Bhargava
,
Maying Shen
,
Nadine Chang
,
Jose M. Alvarez
Cite
Cosmos-Embed1: A Joint Video-Text Embedder for Physical AI
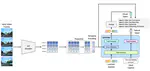
Cosmos-Embed1
is a joint video-text embedder tailored for physical AI applications, including autonomous vehicle (AV) and robotics. It can be used for text-to-video retrieval, inverse video search, semantic deduplication, zero-shot and k-nearest-neighbors (kNN) classification, and as a base model for video curation tasks.
Francesco Ferroni
,
Prithvijit Chattopadhyay
,
Greg Heinrich
,
Mike Ranzinger
,
Roberto Amoroso
,
Alice Luo
,
Andrew Wang
,
Ming-Yu Liu
Cite
HuggingFace
Website
Demo
Cite
×