Roberto Amoroso
Roberto Amoroso
Home
News
Experience
Awards
Publications
Activities
Contact
Light
Dark
Automatic
1
Cosmos-Embed1: A Joint Video-Text Embedder for Physical AI
Cosmos-Embed1
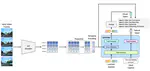
is a joint video-text embedder tailored for physical AI applications, including autonomous vehicle (AV) and robotics. It can be used for text-to-video retrieval, inverse video search, semantic deduplication, zero-shot and k-nearest-neighbors (kNN) classification, and as a base model for video curation tasks.
Francesco Ferroni
,
Prithvijit Chattopadhyay
,
Greg Heinrich
,
Mike Ranzinger
,
Roberto Amoroso
,
Alice Luo
,
Andrew Wang
,
Ming-Yu Liu
Cite
HuggingFace
Website
Demo
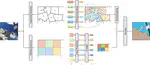
MaPeT: Learning to Mask and Permute Visual Tokens for Vision Transformer Pre-Training
[ CVIU 2025 ]
We propose a novel self-supervised pre-training technique for Vision Transformer called
MaPeT
and a novel image tokenizer called
k
-CLIP
which directly employs discretized CLIP features.
Lorenzo Baraldi
,
Roberto Amoroso
,
Marcella Cornia
,
Lorenzo_Baraldi
,
Andrea Pilzer
,
Rita Cucchiara
PDF
Cite
Code
ArXiv
Perceive, Query & Reason: Enhancing Video QA with Question-Guided Temporal Queries
[ WACV 2025 ]
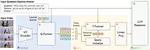
We propose
PQR
, a novel LLM-based framework for video question answering that introduces
T-Former
, a question-guided temporal querying Transformer designed to efficiently extract and integrate video-specific features tailored to a given question.
Roberto Amoroso
,
Gengyuan Zhang
,
Rajat Koner
,
Lorenzo Baraldi
,
Rita Cucchiara
,
Volker Tresp
PDF
Cite
ArXiv
FreeDA: Training-Free Open-Vocabulary Segmentation with Offline Diffusion-Augmented Prototype Generation
[ CVPR 2024 ]
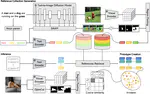
We present
FreeDA
, a novel training-free diffusion-augmented method for open-vocabulary segmentation, which leverages diffusion models to visually localize generated concepts and local-global similarities to match superpixel-based class-agnostic regions with semantic classes.
Luca Barsellotti
,
Roberto Amoroso
,
Marcella Cornia
,
Lorenzo Baraldi
,
Rita Cucchiara
Cite
Project
FOSSIL: Free Open-Vocabulary Semantic Segmentation through Synthetic References Retrieval
[ WACV 2024 ]
We present
FOSSIL
, a novel Unsupervised Open-Vocabulary Semantic Segmentation model that enables a self-supervised visual backbone to perform open-vocabulary segmentation directly on the visual modality by retrieving a support set of generated synthetic references.
Luca Barsellotti
,
Roberto Amoroso
,
Lorenzo Baraldi
,
Rita Cucchiara
PDF
Cite
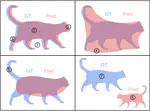
What’s Outside the Intersection? Fine-grained Error Analysis for Semantic Segmentation Beyond IoU
[ WACV 2024 ]
We present a novel method for enhancing semantic segmentation models evaluation by categorizing errors, offering insights into false positives/negatives, and improving performance through the combination of model strengths.
Maximilian Bernhard
,
Roberto Amoroso
,
Yannic Kindermann
,
Lorenzo Baraldi
,
Rita Cucchiara
,
Volker Tresp
,
Matthias Schubert
PDF
Cite
Code
Parents and Children: Distinguishing Multimodal DeepFakes from Natural Images
[ TOMM 2024 ]
We propose a novel deepfake detection method for images generated through Diffusion Models and created a new dataset
COCO-Fake
consisting of 650K generated fake images.
Roberto Amoroso
,
Davide Morelli
,
Marcella Cornia
,
Lorenzo Baraldi
,
Alberto Del Bimbo
,
Rita Cucchiara
PDF
Cite
Dataset
ArXiv
Superpixel Positional Encoding to Improve ViT-based Semantic Segmentation Models
[ BMVC 2023 ]
We present a novel superpixel-based positional encoding technique that combines Vision Transformer (ViT) features with superpixels priors to improve the performance of semantic segmentation architectures.
Roberto Amoroso
,
Matteo Tomei
,
Lorenzo Baraldi
,
Rita Cucchiara
PDF
Cite
Enhancing Open-Vocabulary Semantic Segmentation with Prototype Retrieval
[ ICIAP 2023 ]
We propose a novel open-vocabulary semantic segmentation paradigm based on weakly supervised visual prototypes extracted from image-caption pairs and adopt a retrieval-based approach to combine visual and textual features to enhance segmentation performance.
Luca Barsellotti
,
Roberto Amoroso
,
Lorenzo Baraldi
,
Rita Cucchiara
Cite
A Federated Learning Approach to Traffic Matrix Estimation using Super-resolution Techniques
[ IEEE CCNC 2023 ]
In this work, we propose a super-resolution technique for traffic matrix estimation. We also expand our design by employing a federated learning model to address scalability and improve performance.
Roberto Amoroso
,
Lorenzo Pappone
,
Flavio Esposito
Cite
»
Cite
×