 Overview of our proposed Superpixel Positional Encoding technique.
Overview of our proposed Superpixel Positional Encoding technique.Abstract
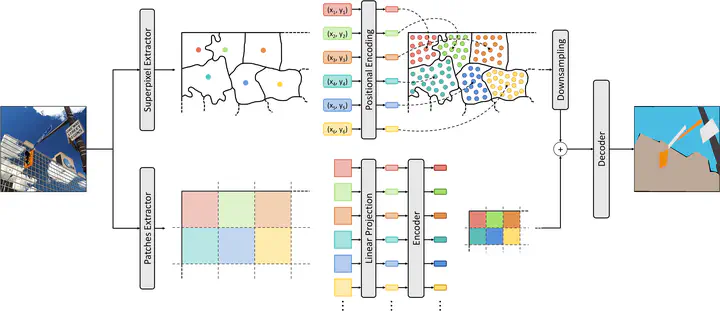
In this paper, we present a novel superpixel-based positional encoding technique that combines Vision Transformer (ViT) features with superpixels priors to improve the performance of semantic segmentation architectures. Recently proposed ViT-based segmentation approaches employ a Transformer backbone and exploit self-attentive features as an input to a convolutional decoder, achieving state-of-the-art performance in dense prediction tasks. Our proposed technique is plug-and-play, model-agnostic, and operates by computing superpixels over the input image. It determines a positional encoding based on the centroids and shapes of the superpixels, and then unifies this semantic-aware information with the self-attentive features extracted by the ViT-based backbone. Our results demonstrate that this simple positional encoding strategy, when applied to the decoder of ViT-based architectures, leads to a significant improvement in performance without increasing the number of parameters and with negligible impact on the training time. We evaluate our approach on different backbones and architectures and observe a significant improvement in terms of mIoU on the ADE20K and Cityscapes datasets. Notably, our approach provides improved performance on classes with low occurrence in the dataset while mitigating overfitting on classes with higher representation, ensuring a good balance between generalization and specificity. The code will be made publicly available.
Roberto Amoroso
Senior Research Engineer @ NVIDIA
VLMs & Multimodal Retrieval
Senior Research Engineer at NVIDIA working on Vision-Language Models for video understanding and large-scale multimodal retrieval.