Cosmos-Embed1: A Joint Video-Text Embedder for Physical AI
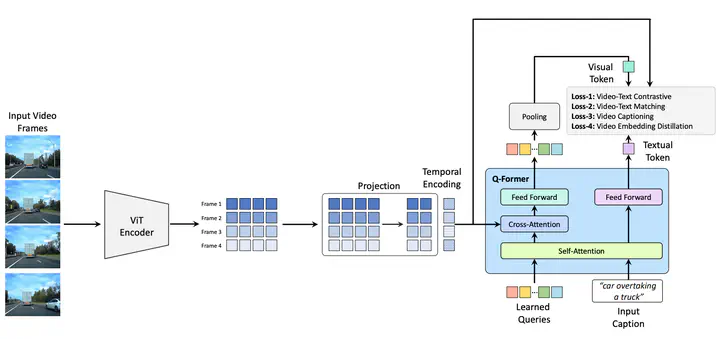 Overview of our proposed Cosmos-Reason1 architecture.
Overview of our proposed Cosmos-Reason1 architecture.Abstract
Cosmos Embed1 is a joint video-text embedder tailored for physical AI. Multi-modal embeddings, particularly joint video-text embedders, are critical for physical AI development pipelines. They enable essential data curation tasks including text-to-video search, inverse video search, semantic deduplication, and targeted filtering. Additionally, these embeddings can also serve as representations to condition on for downstream physical AI models. While existing video-text embedders perform well in general domains, they underperform substantially on physical AI tasks. To bridge this gap, we introduce Cosmos Embed1, a joint video-text embedder specifically tailored for physical AI applications.
Roberto Amoroso
Senior Research Engineer @ NVIDIA
VLMs & Multimodal Retrieval
Senior Research Engineer at NVIDIA working on Vision-Language Models for video understanding and large-scale multimodal retrieval.