Scalable Parallel Prompting for Complex AV Video Captioning
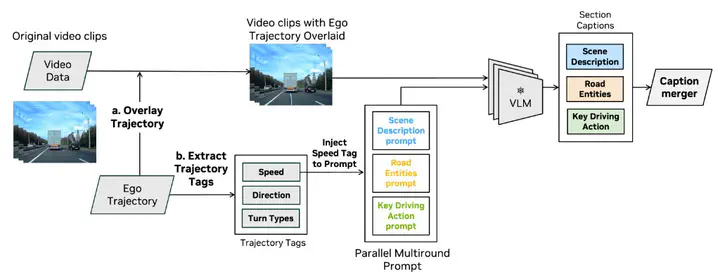 Overview of our proposed pSVLMs framework for scalable metadata-aware video captioning.
Overview of our proposed pSVLMs framework for scalable metadata-aware video captioning.Abstract
Video captioning is crucial for curating datasets to train end-to-end autonomous driving (AD) models. Large video-language models (VLMs) can generate temporally grounded descriptions of driving scenes but face challenges in cost, spatial understanding, the omission of specific details, and compounding hallucinations, where earlier introduced errors compromise the subsequent output. We propose Parallel - SVLMs (pSVLMs), a scalable video captioning framework based on small VLM that produces diverse intermediate captions, which are consolidated into a comprehensive unified description. Captions are first decomposed into structured components describing the scene, road entities, and key driving actions. Then, a parallel multi-round prompting module produces diverse intermediate captions that are consolidated into a unified description. Finally, metadata—such as ego trajectories and basic speed and direction information—is incorporated to enhance 3D scene understanding and improve contextual alignment. Experiments on a large internal dataset show our method produces more comprehensive, granular captions than existing approaches while remaining computationally efficient. This framework enables scalable, metadata-aware multimodal captioning for improved dataset curation and safer AD deployment.
Roberto Amoroso
Senior Research Engineer @ NVIDIA
VLMs & Multimodal Retrieval
Senior Research Engineer at NVIDIA working on Vision-Language Models for video understanding and large-scale multimodal retrieval.