Roberto Amoroso
Roberto Amoroso
Home
News
Experience
Awards
Publications
Activities
Contact
Light
Dark
Automatic
ViT
What’s Outside the Intersection? Fine-grained Error Analysis for Semantic Segmentation Beyond IoU
[ WACV 2024 ]
We present a novel method for enhancing semantic segmentation models evaluation by categorizing errors, offering insights into false positives/negatives, and improving performance through the combination of model strengths.
Maximilian Bernhard
,
Roberto Amoroso
,
Yannic Kindermann
,
Lorenzo Baraldi
,
Rita Cucchiara
,
Volker Tresp
,
Matthias Schubert
PDF
Cite
Code
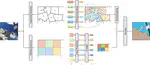
Superpixel Positional Encoding to Improve ViT-based Semantic Segmentation Models
[ BMVC 2023 ]
We present a novel superpixel-based positional encoding technique that combines Vision Transformer (ViT) features with superpixels priors to improve the performance of semantic segmentation architectures.
Roberto Amoroso
,
Matteo Tomei
,
Lorenzo Baraldi
,
Rita Cucchiara
PDF
Cite
Enhancing Open-Vocabulary Semantic Segmentation with Prototype Retrieval
[ ICIAP 2023 ]
We propose a novel open-vocabulary semantic segmentation paradigm based on weakly supervised visual prototypes extracted from image-caption pairs and adopt a retrieval-based approach to combine visual and textual features to enhance segmentation performance.
Luca Barsellotti
,
Roberto Amoroso
,
Lorenzo Baraldi
,
Rita Cucchiara
Cite
Investigating Bidimensional Downsampling in Vision Transformer Models
[ ICIAP 2021 | Best Paper Award sponsored by NVIDIA ]
We explore the application of a 2D max-pooling operator to improve the efficiency of Transformer-based architecture for classification.
Paolo Bruno
,
Roberto Amoroso
,
Marcella Cornia
,
Silvia Cascianelli
,
Lorenzo Baraldi
,
Rita Cucchiara
PDF
Cite
Video
Cite
×