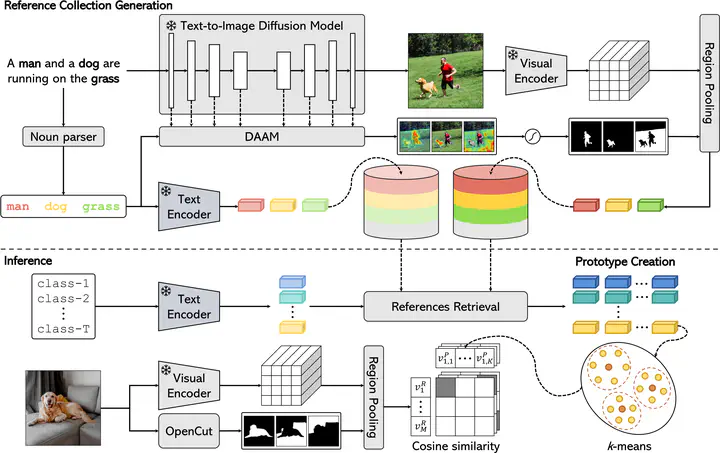
 Overview of the proposed FOSSIL approach for training-free Open-Vocabulary Semantic Segmentation.
Overview of the proposed FOSSIL approach for training-free Open-Vocabulary Semantic Segmentation.Abstract
Unsupervised Open-Vocabulary Semantic Segmentation aims to segment an image into regions referring to an arbitrary set of concepts described by text, without relying on dense annotations that are available only for a subset of the categories. Previous works rely on inducing pixellevel alignment in a multi-modal space through contrastive training over vast corpora of image-caption pairs. However, representing a semantic category solely through its textual embedding is insufficient to encompass the wide-ranging variability in the visual appearances of the images associated with that category. In this paper, we propose FOSSIL, a pipeline that enables a self-supervised backbone to perform open-vocabulary segmentation relying only on the visual modality. In particular, we decouple the task into two components: (1) we leverage text-conditioned diffusion models to generate a large collection of visual embeddings, starting from a set of captions. These can be retrieved at inference time to obtain a support set of references for the set of textual concepts. Further, (2) we exploit self-supervised dense features to partition the image into semantically coherent regions. We demonstrate that our approach provides strong performance on different semantic segmentation datasets, without requiring any additional training.
Roberto Amoroso
Senior Research Engineer @ NVIDIA
VLMs & Multimodal Retrieval
Senior Research Engineer at NVIDIA working on Vision-Language Models for video understanding and large-scale multimodal retrieval.