Enhancing Open-Vocabulary Semantic Segmentation with Prototype Retrieval
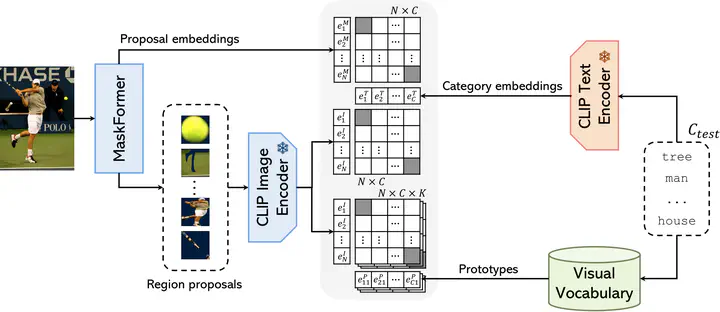 Overview of our proposed method, VOCSeg, for two-stage open-vocabulary semantic segmentation enhanced by visual prototype retrieval.
Overview of our proposed method, VOCSeg, for two-stage open-vocabulary semantic segmentation enhanced by visual prototype retrieval.Abstract
Large-scale pre-trained vision-language models like CLIP exhibit impressive zero-shot capabilities in classification and retrieval tasks. However, their application to open-vocabulary semantic segmentation remains challenging due to the gap between the global features extracted by CLIP for whole-image recognition and the requirement for semantically detailed pixel-level features. Recent two-stage methods have attempted to overcome these challenges by generating mask proposals that are agnostic to specific classes, thereby facilitating the identification of regions within images, which are subsequently classified using CLIP. However, this introduces a significant domain shift between the masked and cropped proposals and the images on which CLIP was trained. Fine-tuning CLIP on a limited annotated dataset can alleviate this bias but may compromise its generalization to unseen classes. In this paper, we present a method to address the domain shift without relying on fine-tuning. Our proposed approach utilizes weakly supervised region prototypes acquired from image-caption pairs. We construct a visual vocabulary by associating the words in the captions with region proposals using CLIP embeddings. Then, we cluster these embeddings to obtain prototypes that embed the same domain shift observed in conventional two-step methods. During inference, these prototypes can be retrieved alongside textual prompts. Our region classification incorporates both textual similarity with the class noun and similarity with prototypes from our vocabulary. Our experiments show the effectiveness of using retrieval to enhance vision-language architectures for open-vocabulary semantic segmentation.
Roberto Amoroso
Senior Research Engineer @ NVIDIA
VLMs & Multimodal Retrieval
Senior Research Engineer at NVIDIA working on Vision-Language Models for video understanding and large-scale multimodal retrieval.