What’s Outside the Intersection? Fine-grained Error Analysis for Semantic Segmentation Beyond IoU
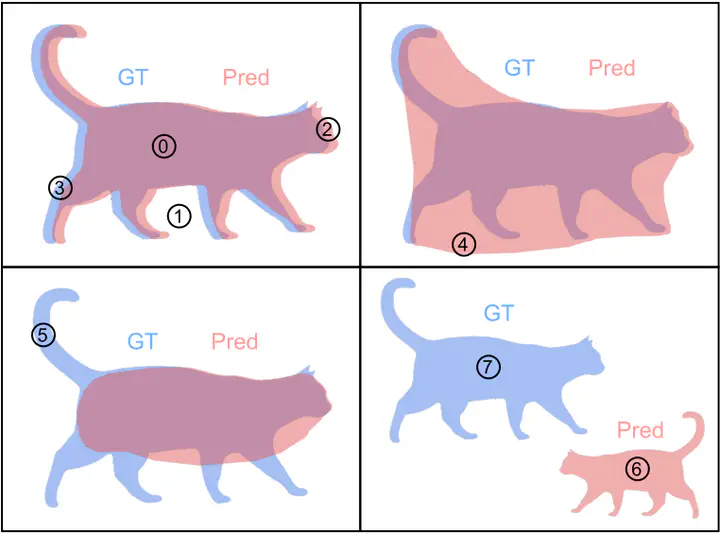 Overview of our proposed error categorization. Each pixel is assigned to one of these categories: 0: true positive, 1: true negative, 2: false positive boundary, 3: false negative boundary, 4: false positive extent, 5: false negative extent, 6: false positive segment, 7: false negative segment.
Overview of our proposed error categorization. Each pixel is assigned to one of these categories: 0: true positive, 1: true negative, 2: false positive boundary, 3: false negative boundary, 4: false positive extent, 5: false negative extent, 6: false positive segment, 7: false negative segment.Abstract
Semantic segmentation represents a fundamental task in computer vision with various application areas such as autonomous driving, medical imaging, or remote sensing. For evaluating and comparing semantic segmentation models, the mean intersection over union (mIoU) is currently the gold standard. However, while mIoU serves as a valuable benchmark, it does not offer insights into the types of errors incurred by a model. Moreover, different types of errors may have different impacts on downstream applications. To address this issue, we propose an intuitive method for the systematic categorization of errors, thereby enabling a finegrained analysis of semantic segmentation models. Since we assign each erroneous pixel to precisely one error type, our method seamlessly extends the popular IoU-based evaluation by shedding more light on the false positive and false negative predictions. Our approach is model- and dataset-agnostic, as it does not rely on additional information besides the predicted and ground-truth segmentation masks. In our experiments, we demonstrate that our method accurately assesses model strengths and weaknesses on a quantitative basis, thus reducing the dependence on timeconsuming qualitative model inspection. We analyze a variety of state-of-the-art semantic segmentation models, revealing systematic differences across various architectural paradigms. Exploiting the gained insights, we showcase that combining two models with complementary strengths in a straightforward way is sufficient to consistently improve mIoU, even for models setting the current state of the art on ADE20K. We release a toolkit for our evaluation method at https://github.com/mxbh/beyond-iou.
Roberto Amoroso
Senior Research Engineer @ NVIDIA
VLMs & Multimodal Retrieval
Senior Research Engineer at NVIDIA working on Vision-Language Models for video understanding and large-scale multimodal retrieval.