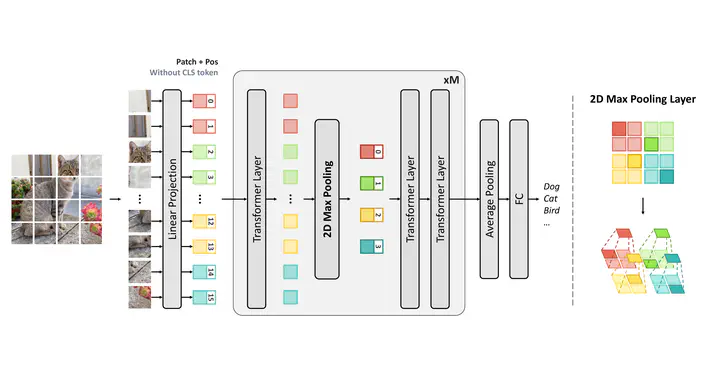
 Overview of the proposed architecture. To reduce computational complexity, we progressively shrink the patches sequence length through 2D max-pooling.
Overview of the proposed architecture. To reduce computational complexity, we progressively shrink the patches sequence length through 2D max-pooling.Abstract
Vision Transformers (ViT) and other Transformer-based architectures for image classification have achieved promising performances in the last two years. However, ViT-based models require large datasets, memory, and computational power to obtain state-of-the-art results compared to more traditional architectures. The generic ViT model, indeed, maintains a full-length patch sequence during inference, which is redundant and lacks hierarchical representation. With the goal of increasing the efficiency of Transformer-based models, we explore the application of a 2D max-pooling operator on the outputs of Transformer encoders. We conduct extensive experiments on the CIFAR-100 dataset and the large ImageNet dataset and consider both accuracy and efficiency metrics, with the final goal of reducing the token sequence length without affecting the classification performance. Experimental results show that bidimensional downsampling can outperform previous classification approaches while requiring relatively limited computation resources.
🔥Best Paper Award sponsored by NVIDIA 
Roberto Amoroso
Senior Research Engineer @ NVIDIA
VLMs & Multimodal Retrieval
Senior Research Engineer at NVIDIA working on Vision-Language Models for video understanding and large-scale multimodal retrieval.